OpenAI nuevamente usó datos con parques de pago para capacitar a su modelo GPT-4O: Informe

Operai está una vez más bajo fuego por sus prácticas de datos, ya que las nuevas acusaciones sugieren que la compañía puede haber capacitado a su último modelo, GPT-4O, en contenido con derechos de autor y con paredes sin embargo sin una autorización adecuada. Las acusaciones provienen del Proyecto de Divulencias de AI, una organización sin fines de lucro AI Watchdog fundada en 2024 por el magnate de los medios Tim O’Reilly y el economista Ilan Strauss.
Acusaciones de uso de datos de capacitación no autorizado
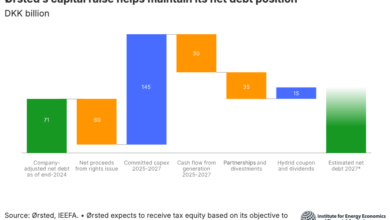
El estudio publicado recientemente del Proyecto de divulgaciones de IA ha provocado controversia al alegar que el modelo GPT-4O de OpenAI demuestra un fuerte reconocimiento de los libros con derechos de autor publicados por O’Reilly Media, a pesar de que no hay acuerdo de licencia entre OpenAi y el editor. Según el informe, GPT-4O muestra un reconocimiento significativamente mayor del contenido de libros O’Reilly con paredes de pago en comparación con modelos más antiguos como GPT-3.5 Turbo.
La investigación empleó un método conocido como «ataque de inferencia de membresía» o DEPOP para probar si el modelo podría diferenciar de manera confiable entre los textos propagados por humanos y las versiones parafraseadas generadas por AI. Si un modelo de IA demuestra la capacidad de distinguir los dos, implica que el modelo puede tener un conocimiento previo del texto original, lo que sugiere su inclusión en los datos de capacitación. El estudio probó 13,962 extractos de párrafo de 34 libros de O’Reilly, concluyendo que GPT-4O reconoció «más contenido de paredes de pago que GPT-3.5 Turbo, con una puntuación AUROC del 82% en comparación con el puntaje de este último justo por encima del 50%.
A pesar de los resultados convincentes, los coautores, incluido el investigador de IA, Sruly Rosenblat, reconocieron limitaciones potenciales en su metodología, señalando que los usuarios podrían haber copiado y pegado extractos de pago en ChatGPT, lo que podría haber introducido el contenido indirectamente. Además, el estudio no examinó los modelos más recientes de OpenAI, como GPT-4.5 y los modelos de razonamiento O3-Mini y O1, dejando preguntas sobre si estos modelos también contienen datos similares.
Un problema de la industria más amplio
Los hallazgos del informe se suman a los desafíos legales en curso que enfrentan OpenAI, ya que la compañía lucha contra múltiples demandas que alegan infracción de derechos de autor y uso de datos no autorizados. Operai y otras compañías líderes de inteligencia artificial han abogado por las restricciones más flojas sobre el uso de datos con derechos de autor para la capacitación de modelos, argumentando que tales prácticas deberían caer bajo la doctrina de uso justo. En particular, Operai ya ha alcanzado acuerdos de licencia con editores de noticias, redes sociales y bibliotecas de medios de acción para asegurar datos, y ha estado contratando periodistas para ajustar la salida de sus modelos.
El proyecto de divulgaciones de IA destaca un problema sistémico que podría afectar la calidad y la diversidad del contenido de Internet. El estudio argumenta que el uso de datos con derechos de autor sin compensación podría reducir los ingresos para los creadores de contenido profesional, lo que potencialmente disminuye la diversidad de contenido en línea. Aboga por una mayor responsabilidad y transparencia en los procesos de capacitación de las compañías de inteligencia artificial, exigiendo políticas que garanticen que los creadores de contenido se compensan cuando se utilizan sus datos.
Si bien Operai continúa defendiendo sus prácticas, los hallazgos del Proyecto de Divulencias de AI han intensificado sin duda el debate sobre la ética de los derechos de autor y los datos dentro de la industria de IA en rápida evolución. A medida que continúan las batallas legales, la cuestión de cómo equilibrar la innovación con los derechos de propiedad intelectual sigue sin resolverse.